Towards Practical Privacy-Preserving Decision Tree Training and Evaluation in the Cloud
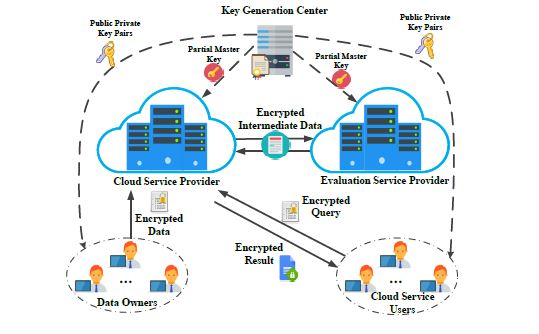 Fig.1 System model
Fig.1 System model
Abstract
Due to the capacity of storing massive data and providing huge computing resources, cloud computing has been a desirable platform for doing machine learning. However, the issue of data privacy is far from being well solved and thus has been a general concern in the cloud-aided machine learning. In this work, we investigate the study of how to efficiently do decision tree training and evaluation in the cloud and meanwhile achieve privacy preservation. Unlike existing cloud server-assisted model training approaches, in our proposed solution, the whole training process is mostly done by the cloud service provider who owns the machine learning model. Since the cloud cannot directly divide the encrypted dataset according to the best attributes selected, we propose a new method for decision tree training without dataset splitting. Precisely, we design three methods for decision tree training with the different tradeoff between privacy and efficiency. In all of these methods, the outsourced data are not revealed to the cloud service provider. We also propose a privacy-preserving decision tree evaluation scheme where the cloud service provider learns nothing about the user’s input and the classification result while the trained model is kept secret to the user who could only learn the classification result. Compared with previous decision tree evaluation work, our scheme achieves desirable privacy preservation against both the user and the cloud service provider, and also minimizes the user’s computation and communication costs. Moreover, besides protecting the data confidentiality, our proposed scheme also supports off-line users and thus has good scalability. The realworld dataset-based experimental results demonstrate that our system is of desirable utility and efficiency.